MAOEC: Un framework de trabajo para analítica digital
Para lograr que los datos generen valor en nuestro negocio, en necesario seguir una guia de pautas que una los objetivos de la empresa con la recoleccion de datos. En este artículo les presento un framework que busca ayudarlos a resolver ese asunto.
Muchas empresas, en especial las pymes, tienen dificultad para crear una recolección de datos web que los ayude a alcanzar sus objetivos. Las causas de esto son varias, entre ellas:
- No se tiene un área dedicada a esto
- El área responsable trabaja solamente con los objetivos de esa área y no con los del resto de la empresa (silos)
- La recolección queda relegada a una agencia externa que solo recolecta lo que la agencia necesita.
- Existe una recolección pero es elemental y no está personalizada para responder a las necesidades del negocio.
- No hay una comunicacion clara entre los que requieren los datos y los desarrolladores que deben implementar la recolección.
Cualquiera sea el caso, para ejecutar correctamente una recolección de datos útil, es necesario un esquema de trabajo y personas que puedan llevarlo a cabo. En este artículo, propongo resolver lo primero, brindándoles una guía de pautas a seguir para que logren alinear los objetivos del negocio y sus equipos a la implementación necesaria para adquirir los datos relevantes, independiente de las herramientas que deseen utilizar.
Este framework de trabajo lo denominó: MAOEC: (si a alguien se le ocurre un nombre más amigable de pronunciar por favor aviseme)
Medición Agnóstica de Objetivos, Eventos y Contexto
En qué consiste el MAOEC brevemente: En identificar los objetivos del negocio, entender qué aspectos de nuestro producto digital nos dan información relevante, y disponibilizar esa información como un suceso de eventos y contextos para cualquier de nuestras herramientas de análisis.
Objetivos
Siempre debemos empezar por los objetivos. Los objetivos nos dan un norte sobre que queremos resolver y que datos necesitamos para resolver eso. Cuando no fijamos los objetivos, caemos en el error de querer medir absolutamente todo lo que se pueda, y esperar que en algún momento esa data nos sirva, lo cual no solo tiene costos técnicos, sino que obstaculiza el trabajo de los analistas disminuyendo la velocidad en la que pueden generar valor por tener que navegar por un sin fin de datos no relevantes hasta alcanzar los útiles.
Primero entonces hay que pensar los objetivos del negocio y su relación con nuestro producto digital. Hay veces que esto es una relación lineal y directa, donde si nuestro negocio es un ecommerce, nos puede interesar solo generar más venta neta del sitio o la app. Pero también nuestro objetivo puede ser querer generar más usuarios registrados, o aumentar la frecuencia de compra de los mismos, o el ticket promedio, etc. Todo depende del estado y las metas del negocio
Por otro lado, después tenemos los objetivos de cada equipo. En el mejor de los casos, los mismos estarán alineados al objetivo general, pero eso no siempre sucede.
Marketing quizás quiere medir la atribución de sus campañas respecto a micro o macro conversiones desglosado por tipos de clientes distintos, por lo tanto va a necesitar una correcta recolección de canales y campañas, y de los datos contextuales de cada cliente.
UX quizás quiere mejorar la interacción con distintos elementos de la experiencia, por lo que necesitará recolectar los datos de clicks e impresiones de dichos elementos en cada espacio digital / página en la que opere. Content Marketing quizás quiere mejorar la interacción con el blog, por lo que va a necesitar medir engagement, scrolling, eventos de contenido compartido. Si el contenido está dividido en categorías, será necesario identificar cada una de ellas dado que pueden tener objetivos distintos.
Si existe un equipo de experimentación / optimización, el mismo necesitará medir los datos relevantes a sus experimentos, como variante que se sirvió al usuario, métrica objetivo del experimento, segmento al que el usuario pertenece, etc.
Como verán, hay mucho que se puede medir. Es por eso que primero hay que establecer objetivos claros y priorizar cada uno, dado que el trabajo de implementar la recolección suele depender del equipo de desarrollo y por lo tanto la velocidad en la que todos estos requisitos se cumplan dependerá del output que ese equipo puede dar. Si se tira todo junto de una sola vez, no habrá claridad de cuándo se podrá comenzar con cada análisis, y puede que los primeros en salir no sean los adecuados para las necesidades de la empresa.
Eventos
Una vez definidos los objetivos, tanto los generales como los de cada equipo, debemos entender que acciones de nuestro producto digital se relacionan a ellos. Algunas pueden ser realizadas por el usuario, otras no.
El ejemplo más básico de todos y que todas las herramientas miden por defecto son los pageviews, o páginas vistas (o screen o pantallas para las apps). Pero dependiendo de nuestro negocio, pueden ser muchos otros y variados. Un ecommerce tiene todas las acciones del funnel de compra, una página de prospectos (leads) tiene los formularios, páginas de contenido pueden tener reproducciones de vídeo, descargas de archivos. En cualquier página con sistema de usuarios está el evento de loguearse o desloguearse, revisar el estado de una orden, contactarse con un equipo de soporte, entre otras.
También pueden haber eventos que no son realizados por el usuario, por ejemplo mostrar un pop up con alguna novedad o descuento, mostrar algún contenido personalizado, hacer una consulta interna a la base de datos, medir el tiempo en página, cargar algún script, forzar un cambio en el DOM, etc.
Ahora bien, de todos los posibles eventos que se puedan medir, no todos estarán relacionados con nuestros objetivos. Es por eso que corresponde identificar aquellos que nos permitan obtener información útil para alcanzarlos. Si nos interesa aumentar la cantidad de prospectos, lo primero que debemos hacer es contar cada vez que un formulario se manda exitosamente. Si queremos saber qué porcentaje de todos se mandan exitosamente, debemos entonces medir también cuantos no se logran mandar. Pero en una primera instancia, para aumentar nuestra cantidad de prospectos puede que no nos interese medir hasta qué profundidad del DOM el usuario scrolleo, y en cambio si queremos medir qué campos del formulario no completo o tuvo problemas para completar.
Gracias a que tenemos los objetivos claros y definidos, identificar qué eventos nos serán útiles se vuelve más fácil, y por lo tanto podemos armar un requisito de implementación de medición ordenado y priorizado.
Contexto
No todos los posibles prospectos, visitante o usuarios de nuestro sitio son iguales. ¿Qué aspectos de nuestro sitio nos permiten identificar esas diferencias? Datos de formulario? Canales de tráfico, selección de una oferta sobre otra, selección de método de envío o de pago? ¿Qué datos que el cliente nos puede brindar de él, de sus preferencias, y que consideramos útiles para nuestros objetivos podemos recolectar?
Esas son las preguntas que debemos contestar a la hora de pensar en los distintos contextos, y ver cómo estos nos ayudan a alcanzar nuestros objetivos. Si por ejemplo nos interesa aumentar la cantidad de prospectos calificados, y el criterio de calificación es que tengan un ingreso aproximado mayor a tanto, o que su empresa tenga más de tantos empleados, debemos poder guardar y disponibilizar esa información de su envío de formulario. Si nos interesa aumentar el ticket promedio total de nuestro ecommerce, puede que sea más fácil lograrlo aumentando apenas el ticket promedio de nuestros clientes que más compran, y por lo tanto tenemos que poder identificar ese dato en la navegación de nuestros clientes.
Casi todas las herramientas por defecto recolectan información contextual del sistema de navegación de nuestros visitantes y de su conexión, como dispositivo, navegador, país. Pero esos datos suelen ser poco relevantes respecto al objetivo que quiero alcanzar. En cambio puede que mis usuarios que pagan con transferencia o efectivo sean ampliamente distintos a los que pagan con tarjeta o en cuotas, siendo un grupo más rentable que el otro. O los que seleccionan un seguro de vida con determinados beneficios, o los que quieren asegurar un auto de un determinado año o modelo.
Muchos de esos pequeños puntos de información nos permitirán tener un mejor entendimiento de por qué camino es más viable alcanzar nuestros objetivos y cómo nuestras decisiones para alcanzarlos afectan a cada grupo de interés. Por eso es importante detectar qué elementos del sitio nos brindan esa información e incluirla en la recolección de datos.
Medición Agnóstica
Una vez que tenemos los objetivos, los eventos y los contextos levantados, es momento de plasmarlo en algún método para recolectarlos. Acá es donde entra el Event Driven Data Layer, o EDDL. Un Data Layer en general es una estructura de datos de Javascript, conformada por un objeto o un array de objetos, que existe dentro del código del sitio web. El EDDL consiste en una estructura de datos en el sitio, que va manteniendo el estado de los eventos que suceden en cada página o pantalla y la información contextual. Es super fácil de implementar y de interpretar, tanto por un humano como por algún sistema que requiera la información que almacena.
En contraste, cuando no se utiliza un dataLayer, sea el EDDL o cualquier otro, la forma de recolectar los datos es “scrapeando” el DOM del sitio, buscando la información en los distintos atributos de cada elemento HTML, por ejemplo el texto de un botón, la clase de un , el id de un formulario. Los triggers más básicos de las herramientas de tagging se basan en estos métodos. El problema y la razón por la que recomiendo usar un Data Layer es porque el DOM de un sitio, sus elementos, son sometidos a muchísimos cambios constantemente, más aún cuando se utiliza un proveedor de sitios externos como un CMS, lo que vuelve la recolección de datos poco resiliente a cambios en el frontend. Si por ejemplo mido como acción el click en un botón en base al valor de su “Id” o “class”, es decir, uso el “id” o “class” como disparador de esta acción en mi herramienta de tagging (GTM por ejemplo), mi recolección dejará de funcionar si esos elementos cambian, ya sea por cambios por el equipo de diseño, o por actualizaciones del CMS, o cambios por alguna herramientas de AB testing. Por lo tanto para conservar la recolección de datos, cada vez que se cambiase un atributo de algún elemento del sitio, habría que avisar a quienes realizan la implementación de tagging, esperar a que cambien los respectivos triggers, testear que la recolección funcione con los nuevos atributos, etc. Esa forma de trabajar pocas veces sale bien, en especial cuando la empresa tiene una agencia que maneja el sitio y otra agencia que maneja los tagging y la recolección, y ambas no tienen un canal directo de comunicación.
Es por eso que recomiendo que utilicen un Data Layer. Si, habrá un equipo de desarrollo que deberá estar a cargo de mantenerlo, pero su funcionamiento puede correr en paralelo a distintos cambios en el sitio, y por lo tanto no tiene una relación de dependencia, lo que lo vuelve más ágil y resiliente.
Para mas informacion sobre el EDDL pueden consultar en: https://jimalytics.com/data-layers/
Por ejemplo un EDDL puede funcionar de la siguiente forma (ejemplo sacado de https://jimalytics.com/data-layers/event-driven-data-layer-eddl-demo/
Para cada pantalla nueva, primero ejecutar lo siguiente:
appEventData.push({
"evento":"Página iniciada"
})Luego enviar data del servidor:
appEventData.push({
"evento":"datosPagina",
"pagina":{
"nombreArticulo":"[article name]",
"categoriaArticulo":"[category name]",
"nombreAutor":"[author name]"
}
})
appEventData.push({
"evento":"dataUsuario",
"usuario":{
"userId":"[user id]",
"fechaRegistro":"[registration date]"
}
})Cuando termina de cargarse toda la página, avisarnos mediante:
appEventData.push({
"evento":"cargaPaginaCompleta"
})Cuando el usuario clickea en un botón de call to action:
appEventData.push({
"evento":"CTA Click",
"data":{
"nombreLink":"[link name]"
}
})Cada uno de los appEventData.push({}) envía nueva información al Data Layer. Como resultado, obtenemos un objeto en nuestro sitio que lleva un registro de los eventos y la data contextual que consideramos relevante recolectar a medida que suceden.
Esta estructura es super fácil de implementar y de interpretar, tanto por un humano como por cualquier sistema que requiera acceder a la información que almacena.
El EDDL es el producto final al que apuntamos para la recolección. Una vez que logramos tener un EDDL, podemos seleccionar la herramienta de tagging y analytics que queramos. El trabajo que queda es mapear la información del EDDL con la estructura de datos de la herramienta que decidamos.
Esto es lo que vuelve al framework una “Medición Agnóstica”. En ningún momento nuestra recolección fue condicionada por las herramientas que decidimos usar. En cambio levantamos toda la data pertinente, y la volvimos accesible en el sitio. Por eso, ahora podemos elegir cualquier herramienta, sea Google Analytics, Adobe, Segment, Snowplow, etc. y para cualquiera ya disponemos de los datos que queramos mandar.
En el caso de Google Analytics, cualquier evento que hayamos decidido recolectar en el EDDL, se puede tratar como un Evento en GA. Y la información de contexto se puede traducir tanto al Event Category, Event Label, o a dimensiones y métricas personalizadas. En el caso de usar Adobe Analytics lo mismo, los eventos siguen siendo eventos, y la información contextual puede mandarse como eVars o sProps.
Respecto a la herramienta de Tagging el caso es el mismo, cualquier herramienta que elijan tiene la funcionalidad de leer objetos del sitio (GTM, Tealium, etc), en este caso el EDDL y acceder a su información, por lo que los eventos que aparecen en el EDDL pueden ser los triggers, para los distintos tags, y la información de cada evento puede pasarse como variables personalizadas para alimentar esos tags. También facilita el orden y ejecución, dado que la información se recolecta por un solo lado (variables) y de ahí se utiliza para cada tag, lo que lo vuelve más fácil de escalar, en vez de tener que crear un solo tag modificado específicamente para obtener esa información necesaria.
Ejemplo Integrador
A continuación veremos un ejemplo de todo lo mencionado anteriormente utilizando como herramientas Google Tag Manager, Google Analytics y Facebook.
Supongamos que nuestro sitio es este blog, y que nuestro objetivo es lograr que más gente se suscriba al newsletter. Para eso necesitamos poder medir la cantidad de visitantes que efectivamente suscriben, pero además queremos saber cuantos tienen la intención de hacerlo, es decir, cuantos clickean en el botón de suscripción.
El botón en cuestión es el siguiente:
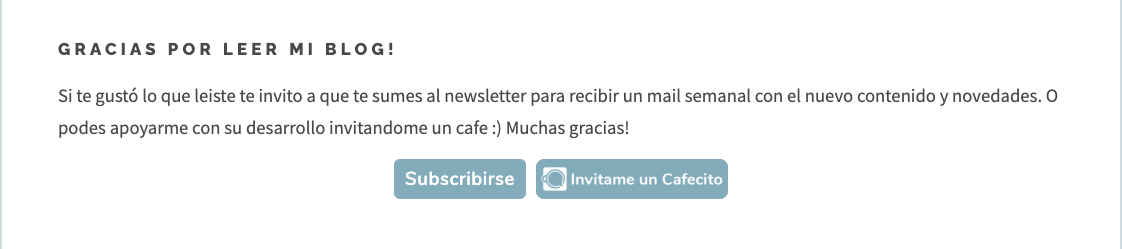
La típica forma en la que esto podría hacerse es utilizando un trigger de GTM de Click en enlace con alguna variable, como la clase del elemento, algo así:
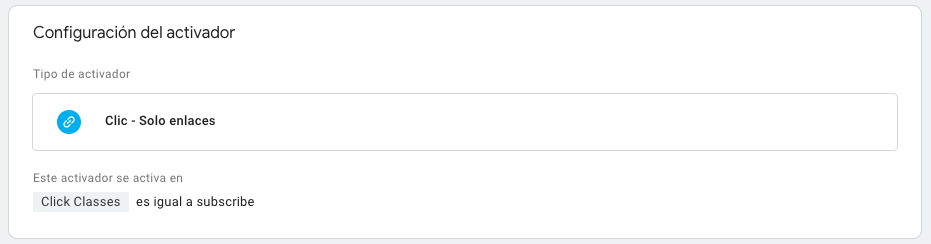
Pero como queremos evitar los problemas que este tipo de implementación puede traer, mencionados anteriormente, vamos a implementarlo mediante el Data Layer.
Por lo tanto, le pedimos a nuestro equipo de desarrollo (o lo hacemos nosotros mismos si es que sabemos cómo) qué cuando alguien haga click en ese botón, se mande un evento a nuestro Data Layer, indicando que se hizo click, y también desde qué artículo del blog fue clickeado, dado que nos interesa saber qué artículos generan la mayor cantidad de suscripciones.
Entonces ahora al hacer click en el botón, el siguiente código corre:
dataLayer.push({ “event”: “click_subscripcion”, “titulo_articulo”: “Test Bayesiano vs Frecuentista” })
Como resultado, si imprimimos el dataLayer en la consola de nuestro sitio, podemos ver:
Perfecto, ya tenemos el evento de interés en nuestro Data Layer junto con información de contexto sobre el mismo (la nota). Ahora nos toca entonces decirle a Google Tag Manager que cuando este evento suceda, realice ciertas acciones. Para eso hacemos lo siguiente:
Vamos a GTM, y creamos un activador del tipo: Evento Personalizado. Y al mismo le indicamos el nombre del evento que queremos medir, en este caso ‘click_subscripcion’. Nos debería quedar algo asi:
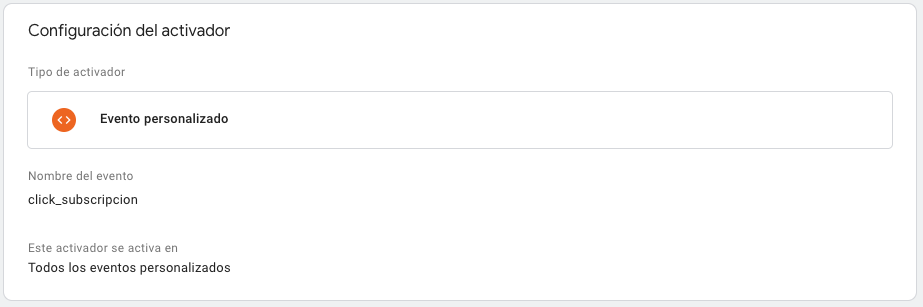
Ponemos para que se active en ‘Todos los eventos personalizados’ porque nos interesa recolectar el click en cualquiera de los artículos del blog.
Ahora nos falta poder acceder al valor contextual, el título del artículo. Para eso dentro de GTM crearemos una variable que del tipo: Variable de Capa de Datos. Nos debe quedar de la siguiente forma:
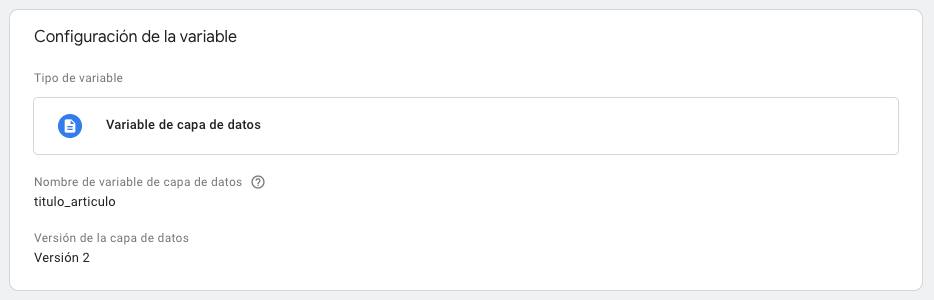
El nombre de la variable de la capa de datos debe coincidir con el nombre que le dimos al momento de crearlo en el Data Layer.
Dado que ya tenemos nuestro activador respecto al evento y nuestra variable para obtener la data de contexto, veamos si funciona:

¡Funciona! ¿Qué es lo que está sucediendo acá? Al hacer click en el botón (paso 1), corre el código que mencione anteriormente, por lo tanto nuestro dataLayer ahora incluye el evento (paso 2). Google Tag Manager reconoce el nombre del evento y lo toma (paso 3). Y luego reconoce que en el dataLayer ahora hay un elemento que coincide con el de la variable que creamos, y toma su valor (paso 4).
Ahora tenemos el evento y el contexto no solo en el Data Layer sino que también lo podemos acceder por nuestra herramienta de Tagging. ¿Y qué hacemos con esto? En este caso haremos dos cosas: Mandarlo como evento a Google Analytics y mandarlo como conversión a Facebook.
Procedemos entonces a crear los respectivos Tags en GTM. Para GA quedaria algo asi:
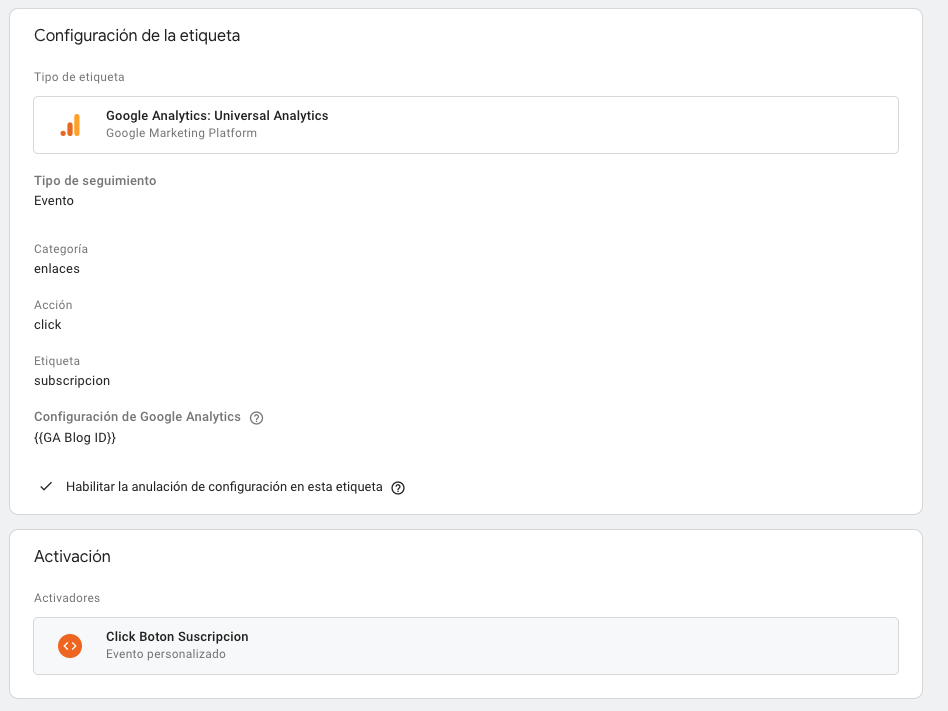
Estamos creando un evento en GA, que se activa cuando en nuestro dataLayer exista el evento que acabamos de configurar, y que como valor de dimensión personalizada envia el titulo del articulo que configuramos como variable.
Para Facebook hacemos algo similar:
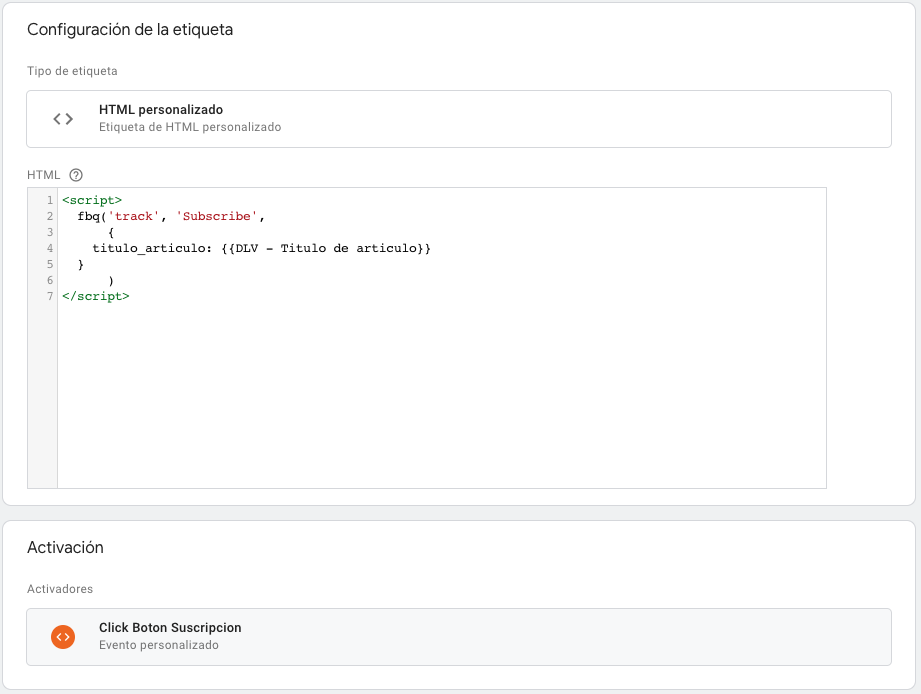
Aca estamos mandando un Evento Estándar de suscripción, pero agregándole un valor de información con el titulo del articulo, igual que como hicimos con GA.
Volvamos a probar si funciona:

¡Perfecto! Se disparan ambas etiquetas tal como planeamos.
Conclusión
Hay muchas formas de encarar la recolección de datos de un sitio o producto digital. Y la adecuada para una empresa no tiene por que ser la misma para otra. Hay que tener en cuenta muchos factores, desde necesidades, equipos, infraestructura, etc. Sin embargo les propuse en este artículo un framework o guía de trabajo que cubre a nivel elemental los puntos más importantes, con el objetivo de que al encarar la recolección de datos en sus empresas, puedan evitar los problemas más frecuentes, y tener un un comienzo sólido respecto al uso de los datos y su relación con los objetivo del negocio.
Por eso lo que más me importa que se lleven es que siempre tengan en cuenta los objetivos, que piensen qué información les puede ayudar a alcanzar dicho objetivos, y que armen una recolección para esos datos que sea resiliente e independiente de las herramientas, dado que estas últimas irán cambiando a medida que las necesidades de la empresa cambia.
Espero que les sea de utilidad, y como siempre, cualquier duda o feedback que tengan al respecto es más que bienvenida.
Gracias por leer mi blog!
Si te gustó lo que leiste te invito a que te sumes al newsletter para recibir un mail semanal con el nuevo contenido y novedades. O podes apoyarme con su desarrollo invitandome un cafe :) Muchas gracias!


Share this post
Twitter
Facebook
Reddit
LinkedIn
Email